

Teljesítménymérés



Az AIDA64 számos, a számítógép egyes komponenseinek teljesítményét mérő benchmarkot tartalmaz. Ezek szintetikus benchmarkok, azaz a hardverek elméleti maximális teljesítményének felmérésére használhatók. A processzor (CPU) és a lebegőpontos műveleteket végző egység (FPU) teljesítményét mérő tesztek az AIDA64 többszálú teljesítménymérő motorjára épülnek, mely – a v3.20 vagy újabb verziók esetében – egy időben akár 640 programszálat és 10 processzorcsoportot is képes kezelni. A motor teljes mértékben támogatja a többprocesszoros, többmagos és HyperThreading technológiájú rendszereket is.
A gyorsítótárak és háttértárak sebessége
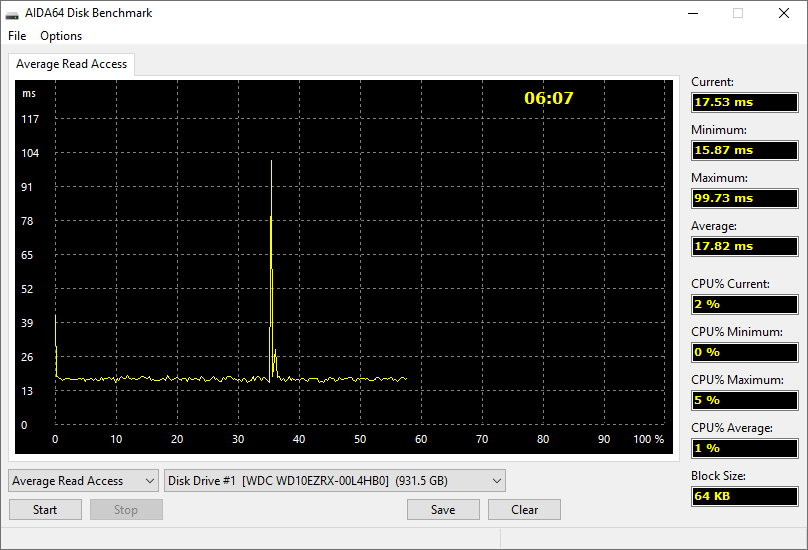
Az AIDA64 külön modult tartalmaz a memória és a gyorsítótár írási, olvasási és másolási sebességének, késleltetésének együttes mérésére, valamint a háttértárolók adatátviteli sebességének vizsgálatára. Az utóbbival nem csupán merevlemezek, hanem RAID-tömbök, optikai meghajtók, Zip-meghajtók és flashmemóriás tárolók teljesítményét is tesztelhetjük.
GPGPU teljesítményének mérése
Ez a benchmarkmodul – mely az Eszközök | GPGPU sebességmérés menüpontra kattintva hívható elő – OpenCL-re épülő GPGPU-benchmarkokat tartalmaz. Ezek a számítógép GPGPU-számítási teljesítményét különféle OpenCL-feladatokkal mérik. Minden egyes mérés futtatható egy időben akár 16 GPU-n is, legyen szó akár AMD, Intel vagy NVIDIA grafikus chipekről, vagy ezek kombinációjáról. Természetesen a modul teljes mértékben támogatja a CrossFire- és SLI-konfigurációkat, valamint a dGPU-kat és APU-kat is. Jelenleg a HSA-eszközökhöz csak előzetes támogatás érhető el. A modul gyakorlatilag az összes olyan eszköz teljesítményét méri, mely GPU-ként jelenik meg az OpenCL-eszközök között.
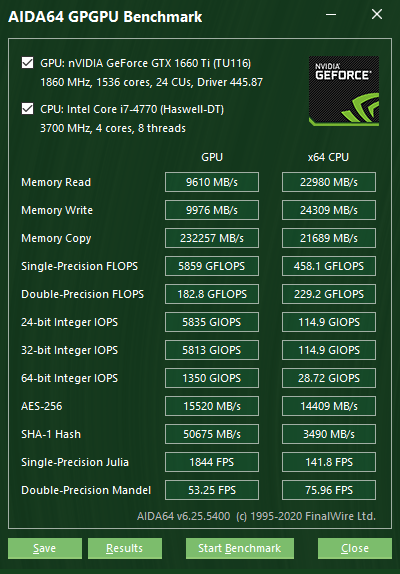
A szoftver ezen átfogó benchmarkokon kívül célzott teljesítménymérő algoritmusokkal is rendelkezik, melyek az oldalmenü Sebesség kategóriájában találhatók. A hatalmas referencia-adatbázisnak köszönhetően ezek esetében az egyes mérések során kapott eredmények más konfigurációk eredményeivel összevethetők. Az AIDA64-ben a következő mikrobenchmarkok érhetők el:
A memória teljesítményének mérése
A memóriaműveletek (olvasás, írás, másolás) esetében a benchmarkok az adott művelet elvégzése során elérhető maximális adatátviteli sebességet mérik. Ezek assembly nyelven íródtak, és az x86/x64, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX és AVX2 utasításkészlet-kiterjesztések használata révén maximálisan optimalizálva lettek az elterjedt AMD, Intel és VIA processzorokra.
A memóriakésleltetés-benchmark azt méri, hogy mennyi idő telik el addig, amíg a processzor megkapja a memóriából bekért adatot. A késleltetés tehát az az idő, mely az olvasás parancs kiadásától kezdve ahhoz szükséges, hogy az adat befusson a processzor integer regiszterébe.
CPU Queen

Ez az integer benchmark a processzor elágazásbecslő logikájának hatékonyságát és a téves becslések hatását méri. A teszt a klasszikus „nyolckirálynő-problémára” keresi a megoldást egy 10x10 mezőből álló sakktáblán. Elméletileg azonos órajelen az a processzor ér el jobb eredményt ebben a mérésben, amely rövidebb futószalaggal rendelkezik, és melyekben a téves elágazásbecslések miatti „büntetés” kisebb. Például egy Northwood magra épülő Intel Pentium 4 processzor (ha a HyperThreading ki van kapcsolva) magasabb pontszámot ér el, mint Prescott magos társa, mivel az előbbi 20, az utóbbi pedig 31 fokozatú futószalagot használ. A CPU Queen mérés integer MMX-, SSE2- és SSE3-optimalizációt használ.
CPU PhotoWorxx

Ez a benchmark a digitális képek feldolgozása során gyakran használt műveleteket hajt végre, egy rendkívül nagy méretű RGB-képen az alábbi műveleteket végzi el:
- a kép feltöltése véletlenszerűen választott színű pixelekkel
- az óramutató járásával ellentétes irányú elforgatás 90 fokkal
- elforgatás 180 fokkal
- különbség
- színtérkonverzió (amely például JPEG-konverzió során használatos)
Ez a benchmark a processzor SIMD integer aritmetikai egységét és a memóriaalrendszert terheli. A CPU PhotoWorxx teszt az azokkal kompatibilis CPU-kon az x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 és XOP utasításkészlet-kiterjesztéseket használja, és támogatja a NUMA, a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
CPU ZLib
Ez az integer benchmark a ZLib tömörítőkönyvtár használatával méri a processzor és a memóriaalrendszer teljesítményét. A CPU ZLib teszt kizárólag az x86-os utasításokat használja, és támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
CPU AES
Ez a benchmark a CPU teljesítményét az AES (Advanced Encryption Standard) adattitkosító eljárás használatával méri. A kriptográfiában az AES egy szimmetrikus kulcsú rejtjelező szabvány, melyet számos tömörítőprogram (köztük a 7z, a RAR, a WinZip) és több lemeztitkosítási megoldás (BitLocker, FileVault, TrueCrypt) használ. A CPU AES teszt az azokkal kompatibilis processzorokon az x86, MMX és SSE4.1 utasításkészleteket használja, illetőleg hardveres gyorsítással fut a VIA PadLock Security Engine-t támogató VIA C3, C7, Nano és QuadCore processzorokon, valamint az AES-NI-t támogató Intel CPU-kon. A mérés támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
CPU Hash
Ez a benchmark a CPU teljesítményét az SHA1 hash algoritmus használatával méri. A kódja assembly nyelven íródott, és az MMX, MMX+/SSE, SSE2, SSE3, AVX, AVX2, XOP, BMI és BMI2 utasításkészlet-kiterjesztések használata révén optimalizálva lett az elterjedt AMD, Intel és VIA processzorokra. A teszt hardveres gyorsítással fut a VIA PadLock Security Engine-t támogató VIA C3, C7, Nano és QuadCore processzorokon.
FPU VP8
Ez a benchmark a Google VP8 (WebM) videokodek 1.1.0-s verziójának használatával méri a processzor videotömörítési teljesítményét (http://www.webmproject.org/). A teszt 1280x720 pixel felbontású (HD ready) videoképkockákat kódol egylépéses módban, 8192 kbps bitrátával és a legjobb minőségű beállítások mellett. A képkockákat az FPU Julia fraktálmodul generálja. A teszt az azokkal kompatibilis processzorokon kihasználja az MMX, SSE2, SSE3 és SSE4.1 utasításkészlet-kiterjesztéseket, és támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
FPU Julia

Ez a benchmark az egyszeres pontosságú (vagy 32 bites) lebegőpontos számítási teljesítményt méri több képkockányi Júlia-fraktál kiszámításával. A teszt assembly nyelven íródott, és az x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA és FMA4 utasításkészlet-kiterjesztések használata révén maximálisan optimalizálva lett az elterjedt AMD, Intel és VIA processzorokra. A mérés támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
FPU Mandel

Ez a benchmark a dupla pontosságú (vagy 64 bites) lebegőpontos számítási teljesítményt méri több képkockányi Mandelbrot-fraktál kiszámításával. A teszt assembly nyelven íródott, és az x87, SSE2, AVX, AVX2, FMA és FMA4 utasításkészlet-kiterjesztések használata révén maximálisan optimalizálva lett az elterjedt AMD, Intel és VIA processzorokra. A mérés támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.
FPU SinJulia

Ez a benchmark a kiterjesztett pontosságú (vagy 80 bites) lebegőpontos számítási teljesítményt méri egyetlen képkockányi módosított Júlia-fraktál kiszámításával. A teszt assembly nyelven íródott, és a trigonometrikus és exponenciális x87-os utasítások használata révén maximálisan optimalizálva lett az elterjedt AMD, Intel és VIA processzorokra. A mérés támogatja a HyperThreading, a szimmetrikus multiprocesszor (SMP) és többmagos processzor (CMP) architektúrákat.