

play_arrow
play_arrow
play_arrow
play_arrow
play_arrow
play_arrow
play_arrow
GPGPU-benchmark



Ez a benchmarkmodul – mely az Eszközök | GPGPU sebességmérés menüpontra kattintva hívható elő – OpenCL-re épülő GPGPU-benchmarkokat tartalmaz. Ezek a számítógép GPGPU-számítási teljesítményét különféle OpenCL-feladatokkal mérik. Minden egyes mérés futtatható egy időben akár 16 GPU-n is, legyen szó akár AMD, Intel vagy NVIDIA grafikus chipekről, vagy ezek kombinációjáról. Természetesen a modul teljes mértékben támogatja a CrossFire- és SLI-konfigurációkat, valamint a dGPU-kat és APU-kat is. Jelenleg a HSA-eszközökhöz csak előzetes támogatás érhető el. A modul gyakorlatilag az összes olyan eszköz teljesítményét méri, mely GPU-ként jelenik meg az OpenCL-eszközök között.
Az OpenCL-benchmarkok nincsenek külön optimalizálva az egyes GPU-architektúrákhoz. Az AIDA64 OpenCL-modulja e tekintetben az OpenCL-fordítóra támaszkodik, ez utóbbi optimalizálja az OpenCL-kernelt az aktuális hardverre. A benchmarkokban használt OpenCL-kernel minden esetben valós időben fordítódik le a GPU OpenCL-meghajtójának segítségével. Ezért mindig javasolt a videodriverek (Catalyst, ForceWare, HD Graphics stb.) legújabb verzióit használni. A fordítás során az OpenCL-fordító következő opciói aktívak: -cl-fast-relaxed-math -cl-mad-enable.
Azért, hogy az eredményeket össze tudjuk vetni, a GPGPU-benchmarkmodul CPU-méréseket is tartalmaz. Ezek azonban nem OpenCL-ben, hanem natív x86/x64-es gépi kódban íródtak, az elérhető utasításkészlet-kiterjesztések – többek között SSE, AVX, AVX2, FMA és a XOP – használatával. E mérések nagyban hasonlítanak az AIDA64 régi CPU- és FPU-benchmarkjaihoz, de ezúttal a maximális számítási teljesítményt mérik (FLOPS, IOPS). A CPU-benchmarkok erősen többszálúsítottak, és az első Pentium óta megjelent minden egyes processzorarchitektúrához külön optimalizációt tartalmaznak.
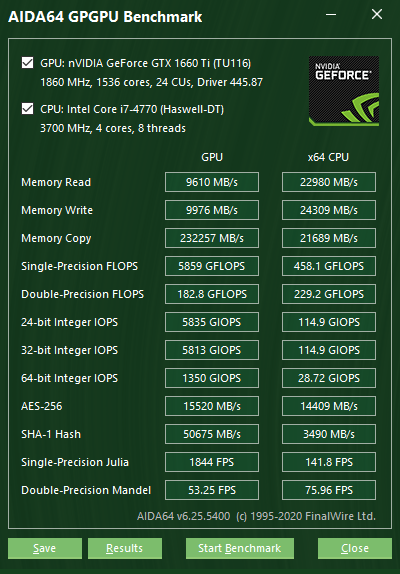
Az alábbi teljesítménymérések választhatók:
Memóriaolvasás (Memory Read)
A GPU és a CPU közti sávszélességet méri, azaz azt a sebességet, mellyel a GPU adatokat képes másolni a saját memóriájából a rendszermemóriába. Ezt a mutatót Device-to-Host sávszélességnek is nevezik. A CPU-benchmark a memóriaolvasás sávszélességét méri, azaz azt a sebességet, mellyel a processzor a rendszermemóriából képes beolvasni az adatokat.
Memóriaírás (Memory Write)
A CPU és a GPU közti sávszélességet méri, azaz azt a sebességet, mellyel a GPU adatokat képes másolni a rendszermemóriából a saját memóriájába. Ezt a mutatót Host-to-Device sávszélességnek is nevezik. A CPU-benchmark a memóriaírás sávszélességét méri, azaz azt a sebességet, mellyel a processzor a rendszermemóriába képes adatokat írni.
Memóriamásolás (Memory Copy)
A GPU saját memóriájának teljesítményét méri, azaz azt a sebességet, mellyel a GPU adatokat képes másolni a saját memóriájából a saját memória egy másik szegmensébe. Ezt a mutatót Device-to-Device sávszélességnek is nevezik. A CPU-benchmark a memóriamásolás sávszélességét méri, azaz azt a sebességet, mellyel a processzor a rendszermemóriában képes adatokat mozgatni egyik címről a másikra.
Egyszeres pontosságú FLOPS
Egyszeres pontosságú (32 bites) lebegőpontos adatokkal méri a GPU ún. MAD (szorzás-összeadás) teljesítményét, melyre FLOPS-ként (másodpercenként elvégzett lebegőpontos művelet) is szokás hivatkozni.
Dupla pontosságú FLOPS
Dupla pontosságú (64 bites) lebegőpontos adatokkal méri a GPU ún. MAD (szorzás-összeadás) teljesítményét, melyre FLOPS-ként (másodpercenként elvégzett lebegőpontos művelet) is szokás hivatkozni. Nem minden GPU támogatja a dupla pontosságú lebegőpontos műveleteket. Például a jelenleg elérhető Intel grafikus processzorok – beleértve az asztali és mobilchipeket is – csupán egyszeres pontosságú lebegőpontos műveletek elvégzésére képesek.
24 bites integer IOPS
24 bites egész adatokkal méri a GPU ún. MAD (szorzás-összeadás) teljesítményét, melyre IOPS-ként (másodpercenként elvégzett integer művelet) is szokás hivatkozni. Ezt az egyedi adattípust az OpenCL definiálja, mivel számos GPU lebegőpontos egysége képes int24 műveleteket végrehajtani, amivel a 32 bites integer műveletekhez képest 3-5-szörös gyorsulás érhető el.
32 bites integer IOPS
32 bites egész adatokkal méri a GPU ún. MAD (szorzás-összeadás) teljesítményét, melyre IOPS-ként (másodpercenként elvégzett integer művelet) is szokás hivatkozni.
64 bites integer IOPS
64 bites egész adatokkal méri a GPU ún. MAD (szorzás-összeadás) teljesítményét, melyre IOPS-ként (másodpercenként elvégzett integer művelet) is szokás hivatkozni. A legtöbb GPU nem rendelkezik 64 bites integer műveletek számára dedikált végrehajtóegységekkel. Ezek az eszközök a 32 bites integer végrehajtóegységeken emulálják a 64 bites műveleteket, így a 64 bites teljesítményük meglehetősen alacsony.
AES-256
Az OpenCL-alapú GPGPU-benchmarkkal a modern grafikus processzorok és APU-k AES-256 adattitkosítási teljesítményét tudjuk mérni.
SHA-1 Hash
Az OpenCL-alapú GPGPU-benchmarkkal a modern grafikus processzorok és APU-k SHA-1 hash algoritmusok végrehajtása során mutatott teljesítményét tudjuk mérni.
Egyszeres pontosságú Julia
Az egyszeres pontosságú (vagy 32 bites) lebegőpontos számítási teljesítményt méri több képkockányi Julia-fraktál kiszámításával.
Dupla pontosságú Mandel
A dupla pontosságú (vagy 64 bites) lebegőpontos számítási teljesítményt méri több képkockányi Mandelbrot-fraktál kiszámításával. Nem minden GPU támogatja a dupla pontosságú lebegőpontos műveleteket. Például a jelenleg elérhető Intel grafikus processzorok – beleértve az asztali és mobilchipeket is – csupán egyszeres pontosságú lebegőpontos műveletek elvégzésére képesek.
Felhasználói felület
A jelölőnégyzetekkel választható ki a CPU, illetve azok a GPU-eszközök, melyek teljesítményét mérni szeretnénk. A CPU jelölőnégyzet állapotát az ablak bezárása után is megjegyzi a szoftver.
A benchmarkok a kiválasztott eszközökön a „Start Benchmark” gomb megnyomásával indíthatók el. Ha minden mérést le szeretnénk futtatni, de csupán a GPU-(ko)n, kattintsunk kétszer a GPU oszlop címkéjére. Ha csupán a memóriaolvasás-méréseket akarjuk futtatni a GPU-(ko)n és a CPU-n egyaránt, kattintunk duplán a Memory Read szövegre! Ha pedig csupán memóriaolvasás-mérést szeretnénk lefuttatni a GPU-(ko)n, kattintsunk kétszer arra a mezőre, ahol ennek a benchmarkeredménynek kell majd megjelennie! Hasonlóképpen indíthatók az egyéb méréskombinációk is.
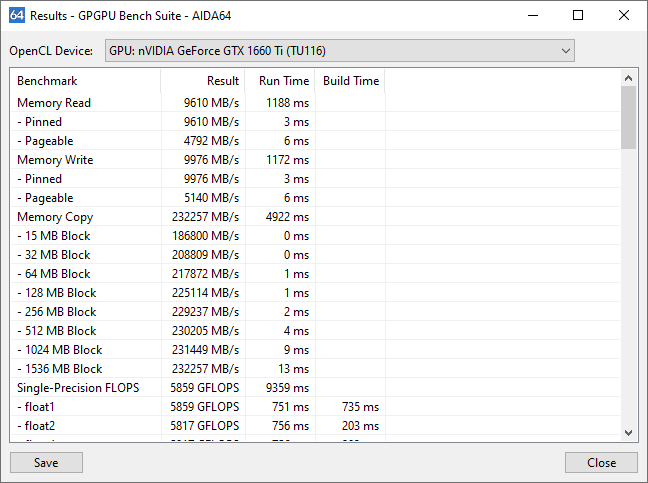
A benchmarkokat a szoftver minden kiválasztott GPU-n egyszerre futtatja több programszálat és több OpenCL-kontextust – de GPU-nként egyetlen kontextust és egyetlen command queue-t – használva. A CPU-mérések ugyanakkor a GPU-benchmarkok befejezését követően indulnak csak el. Jelenleg a GPU- és CPU-benchmarkok nem futtathatók egyszerre.
Ha a rendszerben több GPU is található, az első eredményoszlopban az összes GPU összesített eredménye lesz látható. Az egyes GPU-k eredményét a szoftver ilyenkor összesíti (összeadja), amit az oszlop címkéjében is jelez (például: „4 GPU”). Ha az egyes GPU-k eredményére vagyunk kíváncsiak, válasszuk ki csupán ennek a jelölőnégyzetét, vagy a „Results” gombra kattintva nyissuk meg az eredményeket részletező ablakot!
Ha két GPU-eszközünk van, és kikapcsoljuk a CPU-méréseket a megfelelő jelölőnégyzet törlésével, a panel két GPU-s módba vált. Ilyenkor az első eredményoszlopban az első, a másodikban pedig a második GPU eredményei láthatóak. Ha ebben a módban a két GPU összesített teljesítményére vagyunk kíváncsiak, a benchmarkok lefutása után pipáljuk ki a GPU jelölőnégyzetet, amivel visszaállítjuk az alapértelmezett felületet.